tinyMQTT 目前只是单机 mqtt broker,我的目标是让其支持集群部署,对集群方式进行了一些思考,现记录一下初步暂定的方案和其他可能的方案,以免忘记。现在的思考受制于知识储备,难免不周,留待日后更正吧。
初步暂定方案
一个 mqtt broker 的集群至少需要维护三种重要的数据结构:本地订阅树,全局主题树,全局路由表。本地订阅树是每台 broker 私有,可以看成是 topic –> clients 的映射,记录了哪些客户端订阅了本机的哪些 topic。全局主题树、全局路由表是所有 broker 共享的,应在 broker 之间保持保持一致。全局路由表是 topic –> broker nodes 的映射,记录哪些 broker 对哪些 topic 感兴趣,例如,当某个客户端在 broker A 订阅了 /topics/#,那么全局路由表中应新增 /topics/# –> [broker A] 的条目,表示 broker A 对 /topics/# 感兴趣,另一个客户端在 broker B 订阅了 /topics/#,全局路由表变为 /topics/# –> [broker A, broker B],只有本地新增 topic 时才需要更新路由表,比如又有其他客户端在 broker A 上订阅了 /topics/#,全局路由表不需要更新。当收到客户端的 publish 消息时,先查找路由表,找出所有对该消息对应主题感兴趣的 broker,将该消息发往所有感兴趣 broker,消息到达每台 broker 后,由其自己查找本地订阅树,转发到所有订阅了该主题的客户端,保证在不同 broker 上订阅相同主题的客户端都能收到该消息。全局主题树用于加速路由的查找。
目前的想法是先不考虑消息的持久化,publish 消息只存在于 broker 内存。但是路由表,全局主题树需要持久化,便于 broker 宕机恢复,而且需要 broker 之间保持一致性 (最终一致性)。初步暂定方案如下:
集群成员发现
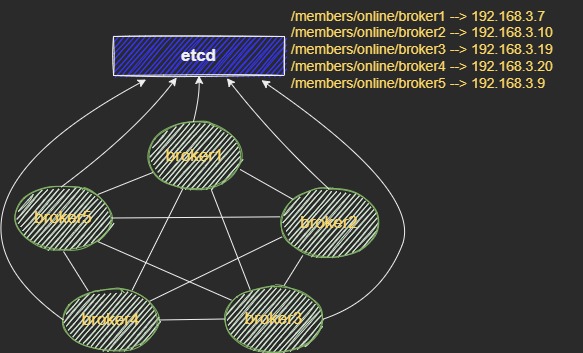
使用 etcd 来实现集群节点之间自动发现,指定一个共享的 prefix,例如 /members/online,当一个 broker 想要加入集群时(设 broker name 为 broker1),它先调用 put 接口,创建一个 /members/online/broker1 –> broker1 IP 的 key value pair,再调用 watch 接口,监听 /members/online 这个 prefix。这里需要加分布式锁,保证 put 和 watch 之间没有其他 broker 的 put。当集群中已有的 broker 监听到 /members/online 下的 put 事件时,它需要主动与新增的 broker 建立 tcp 连接。这样在正常情况下集群间的 broker 两两之间都有 tcp 连接。每个 broker 对应的 key 与一个 lease 绑定,定期续约,相当于 broker 与 etcd 之间的心跳维持。
订阅消息的复制
订阅消息我打算采用类似无主复制的方式,但和一般的无主复制不同,当一个 broker 上新增 topic 时,由它自己负责将这一路由表更新请求广播给其他所有 broker,其他 broker 收到后更新自己的路由表。当然这样会导致不同 broker 更新路由表不是全序的,但在这一特定场景下似乎并不重要,比如 broker1 的路由表中 /topic 一项下先添加 broker2,后添加 broker3,而 broker5 的路由表中 /topic 一项下先添加 broker3,后添加 broker2,效果都是一样的,因为路由表的每一项对应的是个 node 集合,是顺序无关的。所以这里的最终一致性其实指的是所有 broker 的路由表中都有相同的项,每项下都包含相同的 node 集合,集合中的顺序无所谓。所以要实现路由表的最终一致性,只需要每个 broker 都执行过来自其他 broker 的路由表更新请求即可。
如何保证最终一致性
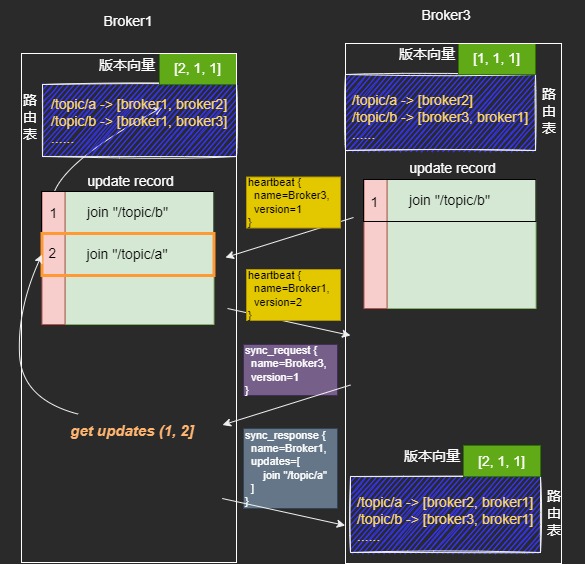
每个 broker 维护一个路由表的版本向量,有 N 个节点版本向量就是 N 维。比如上图每个 broker 初始版本向量都是 [0, 0, 0, 0, 0]。这里把广播路由表更新请求的那个 broker 称为路由更新的发起者,假设客户端在 broker1 上进行订阅,使得 broker1 上产生了新的 topic,broker1 广播路由表更新,那么 broker1 就是本次更新的发起者。当一个 broker 发起更新时,它首先将版本向量中自己对应的那一维 + 1,将其连带消息广播出去,此外还要在本地的 update_record 中记录此次操作,大概这样:
1
2
3
4
5
6
7
8
9
10
11
12
13// 发起者
// self_name = "broker1"
void save_update_record(int version, const char* topic); // 保存由自己发起的更新记录
void add_self_to_router(const char* topic); // 把自己的节点名添加到路由表的 topic 下
void broadcast(int version, const char* topic); // 广播路由表更新消息
void update_router(const char* topic) {
versions[self_name]++;
add_self_to_router(topic)
save_update_record(versions[self_name], topic)
broadcast(versions[self_name], topic);
}当一个 broker 收到一条路由更新请求时,它首先检查请求中的 version 是否等于本地记录的版本向量对应维的值 + 1,如果是,执行更新,并将本地版本向量对应维 + 1,否则不做任何事。大概如下:
1
2
3
4
5
6
7
8
9
10
11// 被动更新者
void on_update_router(update_req req) {
if(req.version == versions[req.peer_name] + 1) {
apply_update(req.update);
versions[req.peer_name]++;
}
else {
// do nothing
}
}那么如何保证最终一致性呢,我的想法是在节点之间的心跳消息中带上自己对应那一维的版本号,一个 broker 要定期向其他所有 broker 发送心跳消息,而当它收到其他节点的心跳后,将心跳消息携带的版本号和本地记录的对应 broker 的版本号比较,如果本地版本号 < 心跳携带的版本号,说明自己落后了,要向对方发送请求同步的消息,并携带自己本地的版本号。当一个 broker 收到请求同步消息后,查找自己的 update_record,将 (请求同步消息中的 version, 本地 version] 范围内的更新记录发送给对方。接收方 apply 这些更新并更新本地版本向量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// self_name = "broker1"
void request_sync(const char* peer_name, int local_version); // 向 peer_name 请求同步
void send_sync(const char* peer_name, int offset) // 将本地 update_record 中 offset 以后的记录同步给peer_name
void on_heartbeat_message(heartbeat_msg msg) {
if(versions[msg.peer_name] < msg.version) {
request_sync(msg.peer_name, versions[msg.peer_name]);
}
...
}
void on_sync_request(sync_req req) {
int offset = req.version;
send_sync(req.peer_name, offset);
}
void on_sync_response(sync_resp resp) {
for(int i = 0; i < resp.updates.size; i++) {
apply_update(resp.updates[i]);
versions[resp.peer_name]++;
}
}其实 broker 本地的版本向量就是记录了对于集群中的每个 broker,已经执行了几次对方发起的更新。另外每个 broker 只需要为由自己主动发起的更新维护一个 update record 队列,不需要记录被动执行的更新。假设某时刻 broker3 缺失由 broker1 发起的一个更新,同步过程如图:
如何处理宕机恢复
为了能在宕机恢复时减少与其他 broker 同步的通信量,可以定期将本地版本向量与路由表持久化。或许可以以树形结构把路由表存在 sqlite 里。重启以后先把路由表和版本向量恢复,再加入集群,接下来上述的心跳机制会自动同步它缺失的更新。
如何处理网络分区
感觉处理网络分区是最棘手的,因为情况多样,可能是对称分区或者非对称分区。不管怎样必须保证集群在任意时刻仅有一个分区在提供服务,否则如果同一时刻集群中有多个网络分区都在提供服务,那么会出现客户端认为自己订阅成功,但收不到其他客户端在另一个分区的 publish,所以需要在某些情况下牺牲 Availability 照顾一下 Consistency。我的想法是:当一个 broker 收不到大于等于 N / 2 个节点的心跳时,就自动停止服务,任何客户端的 subscribe/unsubscribe、publish 消息都会返回错误(qos 0 除外,反正 qos 0 本身就不保证送达)。并且定期重试加入集群。这样应该是可以避免多个分区同时服务的,可以尝试反证一下,假设 broker1、broker2 之间没有通路,如果broker1 能收到 N / 2 个节点的心跳,那么算上 broker1 自己,broker1 所在分区节点数至少是 (N / 2) + 1,同理,broker2 所在分区节点数也至少是 (N / 2) + 1,一个集群不可能有两个节点数量为 (N / 2) + 1 的分区,即 broker1 和 broker2 所在分区必有公共节点,与假设矛盾。但是又有新的问题,以上的订阅复制和同步等方案需要节点之间是两两连接的,在出现非对称分区的时候怎么办呢?暂时只能想到经过其他节点转达,如果 broker1,broker2 之间不能直连,那就把包标上源 broker name 和目的 broker name 后广播,把其他节点当路由器用,这应该会给集群内部带来大量通信负担,不过也想不出来啥好办法。
其他方案
- 采用主从复制的模式
- gossip 协议
- …