Parallel Query Execution
这节课比较偏理论,讲的是请求的并行执行方式,简单记录一下。首先要区分 Parallel DBMS 和 Distributed DBMS,前者的资源和组件之间的物理距离是很近的,且它们之间的通信是快速可靠的,比如一台机器上的多个进程或线程;后者的资源之间距离远,比如位于跨地区的不同机房,它们之间通信较慢,且不可靠(即使使用 TCP)。这节课专注于 Parallel DBMS。
Process Model
worker 是指一个负责执行执行具体的任务并返回结果的单位。Process Model 是数据库的处理模型,类似服务器的并发模型,有 Process Per Worker、Thread Per Worker 和 embedded 三种。
Process Per Worker
多进程模型,每个 worker 工作在一个进程中,客户端与 dispatcher 连接,dispatcher 负责分配具体的任务给 worker,使用共享内存来共享全局的数据结构(比如 buffer pool)。 好处是一个 worker 崩溃不会使整个系统崩溃。此外还因为不同操作系统的线程 API 可能不同,但进程 API 却相对统一(fork),所以可移植性好一些。
Thread Per Worker
多线程模型,一个 worker crash 会导致系统退出。此外还提到了 SQL Server 一个非常有意思的技术——SQL OS,是指将 OS 作了一层抽象,DBMS 不直接使用原生 OS 的系统调用,而是通过 SQL OS 层与操作系统交互。更重要的是它支持非抢占式的线程调度方式,线程需要在用尽时间片后主动 yield() 返回 scheduler,感觉很像协程啊。这样数据库的 scheduler 就有了完全的控制权,可以决定 worker 的执行顺序,而不是依赖操作系统调度。
Embedded
就是指本身不是一个独立的服务,而是以库的形式嵌入其他应用程序的数据库,像 sqlite、leveldb。它们的并发模型取决于应用程序如何使用。
Inter-Query Parallelism 和 Intra-Query Parallelism
Inter-Query Parallelism 是指同时执行多条不同的 query,如果同时执行多条会改变数据库状态的更新 query,会涉及到并发控制的问题(lecture 15);Intra-Query Parallelism 是指并行地执行一条 query 包含的不同操作,比如下面这个并行 Partitioned Hash Join,在完成分区以后,可以把每个分区内的 Join 分配给多个 worker:
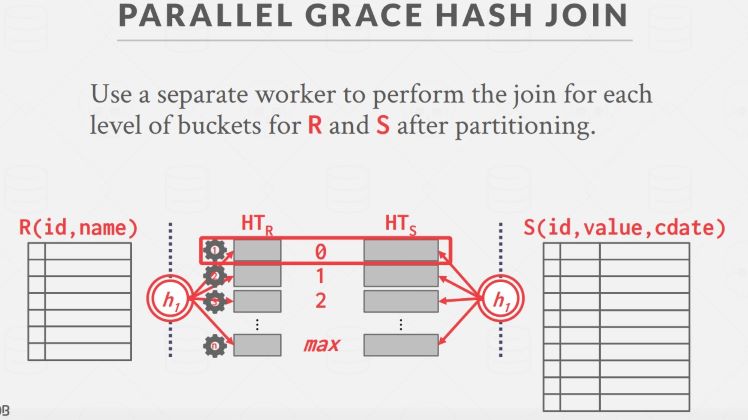
Intra-Query Parallelism 又分为三种方式:
- Intra-Operator
- Inter-Operator
- Bushy
Intra-Operator
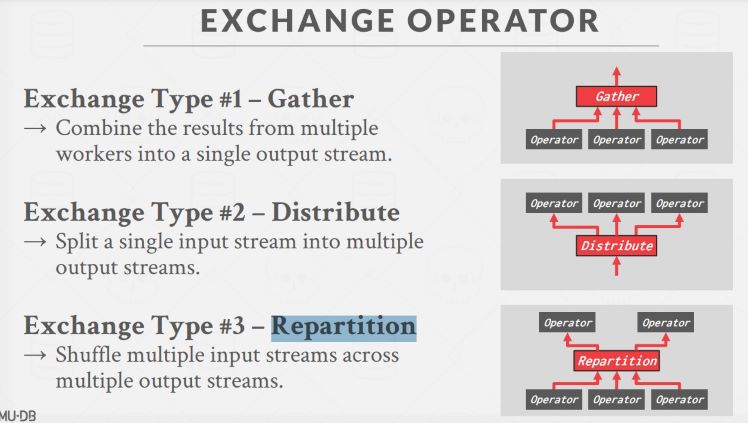
Intra-Operator 是对 operator 进行横向拆分,拆分出的多个 operator 进行的是相同的操作,只是每个负责数据的一个子集。(Decompose operators into independent fragments that perform the same function on different subsets of data.) 为此还需要一种特殊的 exchange operator,主要有三种功能:收集多个并行 worker 的工作结果(Gather)、将输入数据分派给多个 worker 进行处理(Distribute)、将多个输入汇总,再分配给多个 worker(Repartition)
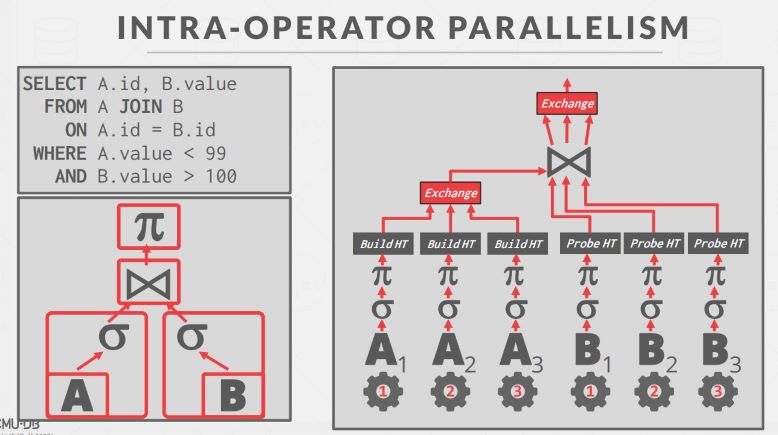
在这个 Hash Join 中,先分配三个 worker 并行地为外表建立 Hash Table,结果由 exchange operator 汇总,再分配三个 worker 并行地 probe:
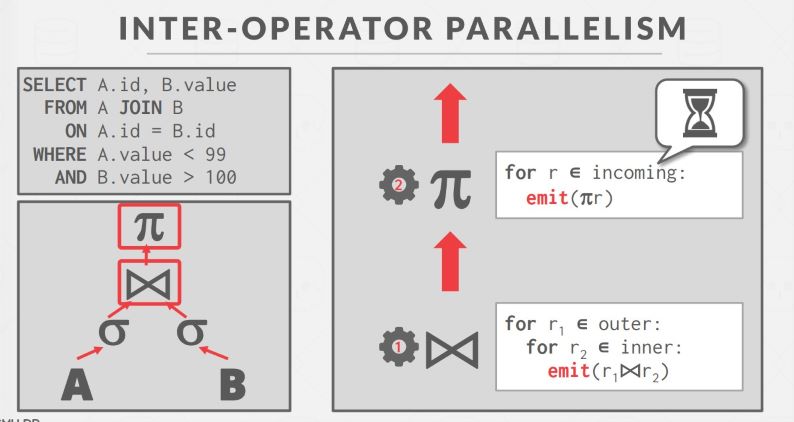
Inter-Operator
Inter-Operator 是将一个 query 纵向分割,把不同的操作分配给不同的 operator,每个 operator 不断接收输入并产生输出,这种并行是发生在不同层的 operator 之间的,如果下层 operator 没有向上层提供数据,上层 operator 将会阻塞等待。
Bushy 就是以上两种并行方式的混合。
I/O Parallelism
当数据库系统的瓶颈不在 CPU 而是磁盘时,再多的多核优化都是浪费的,需要进行 I/O 并行。可以通过组建 RAID 的方式将数据分散到多个存储设备上,而数据库本身对此应该是无感知的。