Query Execution
这节课主要讲的是几种数据处理的模式(Processing Model)、底层数据获取的方式(Access Method)、修改请求(Modification Query),即增删改操作,以及表达式求值(Expression Evaluation)。
Processing Model
Processing Model 规定了执行一个 query plan 时数据的流向,以及 operator 之间传递什么样的数据,主要有以下三种 processing model:我理解的它们之间的主要区别是 operator 每次向上层返回数据的多少。
- Iterator Model
- Materialization Model
- Vectorized Model
Iterator Model
迭代器模型,也叫火山模型或流水线模型。每个 operator 要实现一个 Next() 方法,当被上层调用时,返回一个 tuple,如果没有数据可返回,就返回 null。上层 operator 一般会循环调用子 operator 的 Next() 方法获取数据。
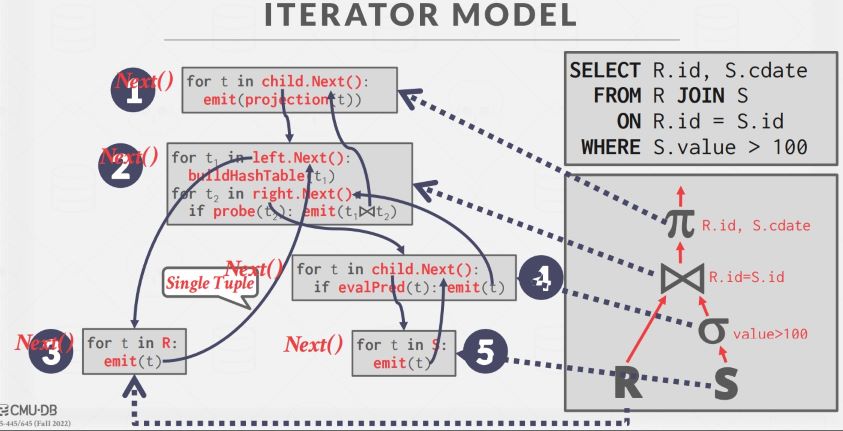
这个例子中最上层的 projection operator 调用 join operator 的 Next(),Join operator 使用的是 Hash Join,需要得到外表的全部数据来构建哈希表,所以它会先循环调用左孩子的 Next() 直到其返回 null,再调用右孩子的 Next(),在此期间是阻塞上层调用的,这类需要阻塞直到拿到子 operator 所有数据的 operator 也叫做 pipeline breaker,包括 Join、Subqueries, Order By。迭代器模式在处理 LIMIT 时十分方便,因为可以随时停止,只需不再调用子节点的 Next() 就好了。但是由于有多少条数据就要调用多少次 Next(),函数调用开销很大。
Materialization Model
物化模型下,一个 operator 会一次性输出其所有处理过后的数据,即它会将所有输出“物化”成一个单一的结果返回给上层,所以使用此模型的数据库会将诸如 LIMIT 等条件下推,以避免获取过多没用的 tuple。operator 的输出可以是完整的 tuple,也可以是列的子集,前者用于 NSM(行存储),后者用于 DSM(列存储)。关于 NSM 和 DSM
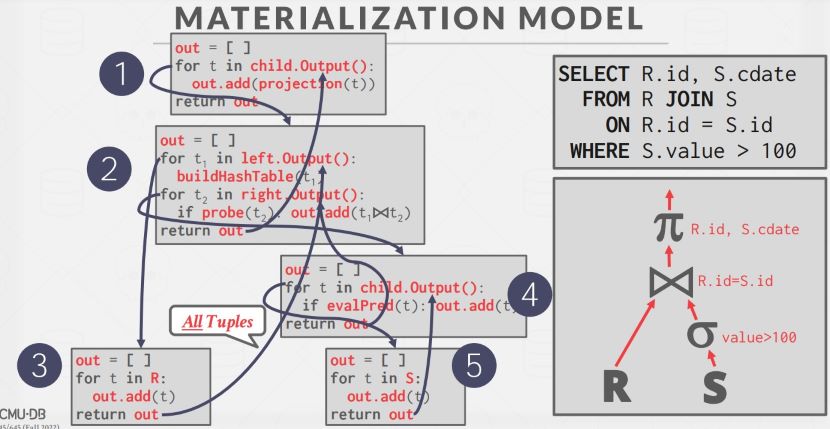
比较适合 OLTP 而不是 OLAP,因为 OLTP 不会一次性读大量的数据,OLAP 会产生大量中间结果。
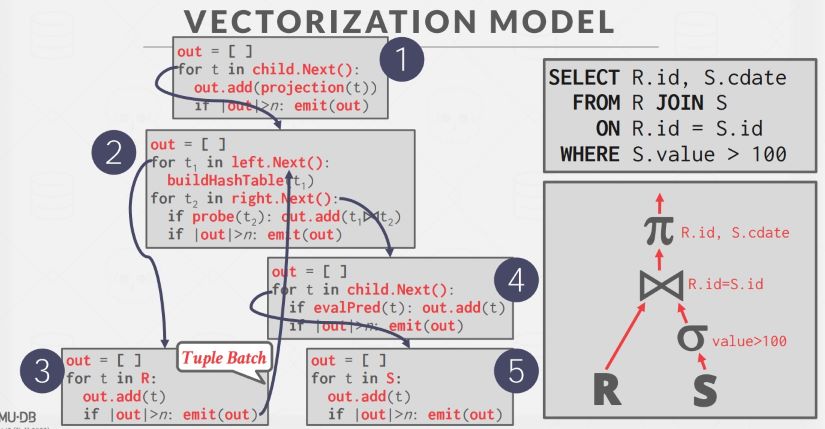
Vectorized Model
Iterator Model 和 Materialization Model 是两个极端,一个一次返回一条数据,一个一次返回所有数据,Vectorized Model(Batch Model) 取个折中,一次返回一批 tuple。这种方式减少了函数调用开销,适合 OLAP 系统,而且可以应用 SIMD 优化。
Plan Processing Direction
- Top-to-Bottom:上层 operator 通过函数调用从下层拉取 tuple
- Bottom-to-Top:从叶节点开始,向上层推送 tuple
Access Method
指的是获取表中数据的方式,可以对应 query plan 的叶子节点,主要有三种方式:
- Sequential Scan
- Index Scan
- Multi-Index Scan
Sequential Scan
顺序扫描就是把表的每个 page 依次读入内存,遍历其中每个 tuple。数据库会记录上次遍历到了哪个 page 的哪个 tuple。顺序扫描虽然效率最低,但最通用,有时甚至只有这一种选择。
Data Skipping
Data Skipping 是 Sequential Scan 的优化方式之一

有两种 Data Skipping 的方式,一种是 Approximate Queries,是有损的,不保证结果百分百准确,只是大概的估计,Andy 举的例子是比如说我想知道自己网站的浏览人数,只返回大概人数就好了,比如一万人,差个一千其实无所谓。另一种 Zone Maps 是无损的,基本思想是数据库会为原始数据维护一些统计信息,比如最小最大值、平均值等等,通过这些信息有时可以直接跳过落在范围之外的查询:

这个例子中通过查询 Zone Map 可知这段数据最大才 400,所以不用去遍历原始数据了。
Index Scan
使用索引来查找满足条件的 tuple。一个表可能有多个索引,具体选择哪个索引还要取决于查询语句、索引所在属性值的分布特征等条件,比如这个例子:

情况 1 中使用 dept 的 index 更好,因为其更具选择性,一次可以筛选掉大部分的数据,同理情况 2 中选用 age 的 index 更好。
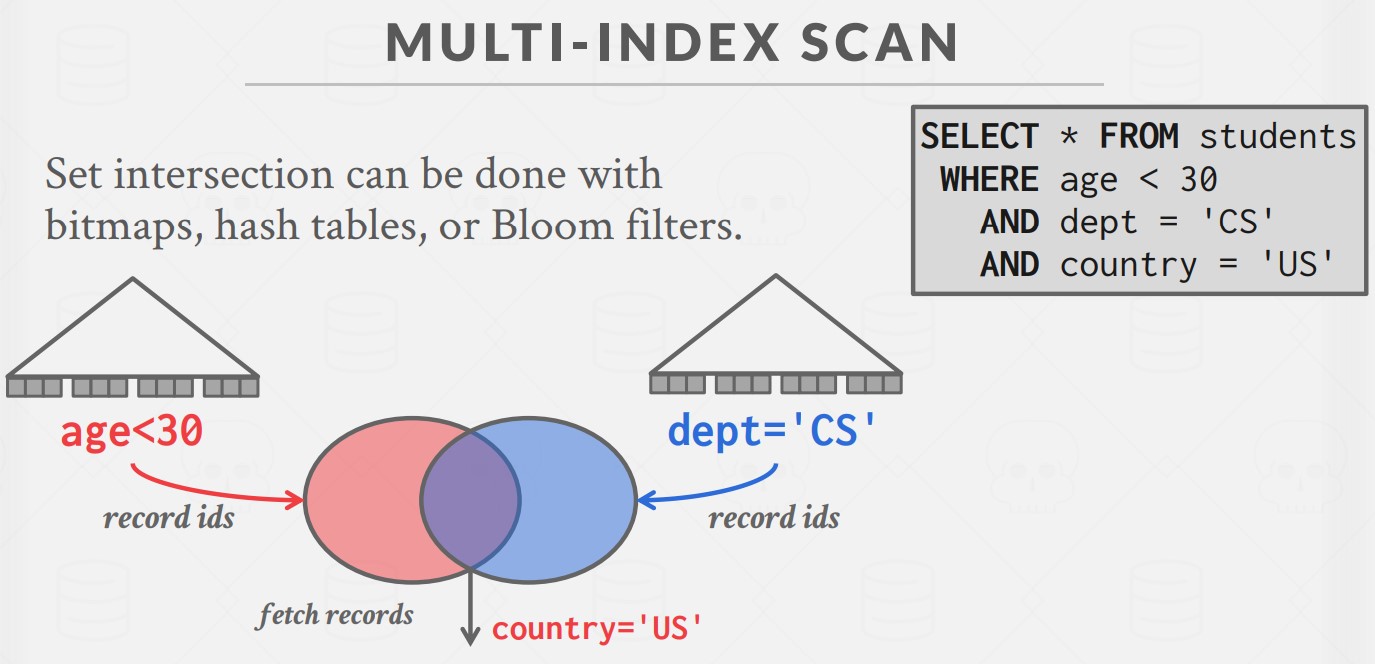
Multi-Index Scan
如果多个属性上都有索引,又都出现在条件表达式里了,那么可以用 Multi-Index Scan,就是将每个 index 筛选出来的数据求交集(AND)或并集(OR),其中求交集可以用 bitmap、哈希表或者 bloom filter:
Update Query Problem
在更新数据的时候需要特别注意“万圣节问题”,简单描述就是当要对满足一定条件的 tuple 进行更新时,首先通过索引或者顺序扫描查找到一个符合条件的 tuple,将其删除,再插入更新后的 tuple,这个新 tuple 可能会处于当前扫描位置的后面,导致之后会再次扫描到这个 tuple,如果这时它依然满足条件,那又会更新它一次。一条更新语句多次更新一个 tuple 显然是不符合语义的:

这里需要先删除再插入是因为要保证 B+ Tree 索引的正确性,是无法原地更改属性值的。
Expression Evaluation
数据库对于 WHERE 从句的一般做法是将其转化成一颗表达式树,对于每个 tuple,都要遍历一遍这棵树:
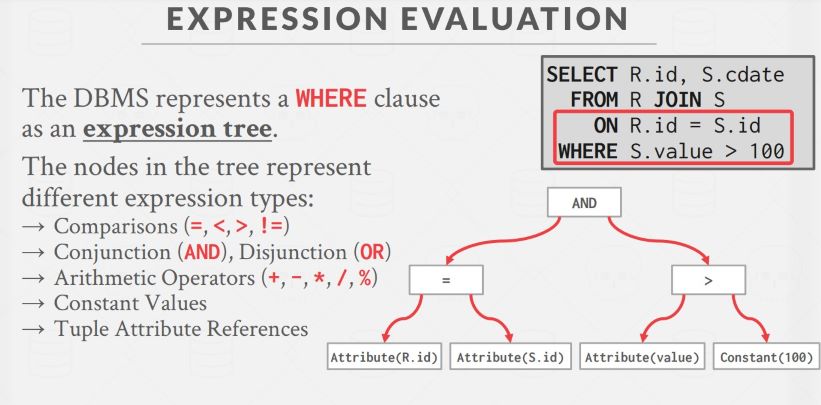
显然性能是不怎么样的。一种优化是采用 JIT (即时编译),就是将 WHERE 从句转化成一个与之等价的函数,在运行时将其编译成字节码,对于每个 tuple 直接调用这段函数即可,会非常快。